From Manual Entry to Auditable AI Pipeline
- Documents arrive by email
- Staff keys data manually
- Errors cascade downstream
- Rework and corrections
- Compliance gaps
- AI classifies and extracts
- Schema validation + confidence scoring
- Staff reviews exceptions only
- Auto-exports to ERP/CRM
- Full audit trail, every field
A growth-stage accounting firm was constrained by manual document intake and data entry. We built an AI-assisted document processing workflow that converts incoming PDFs into validated structured records, routes low-confidence fields to staff review, and maintains a full audit trail for compliance.
Scope: Ingest, classify, extract, validate, route exceptions, integrate, audit. Not a full ERP rebuild.
What transfers: The pattern of schema-based extraction with human checkpoints applies anywhere you have repeatable document types and need defensible records.
What Was Broken
Manual document processing had become an operational constraint. Staff spent hours on data entry instead of client work, and errors created downstream headaches.
- Manual entry created bottlenecks during peak periods
- Errors cascaded into downstream workflows
- Variability across staff increased rework
- Compliance risk from incomplete records and weak traceability
- High-opportunity staff time consumed by extraction tasks
The existing process could not scale with the firm's growth, and adding headcount was not sustainable.
What We Built
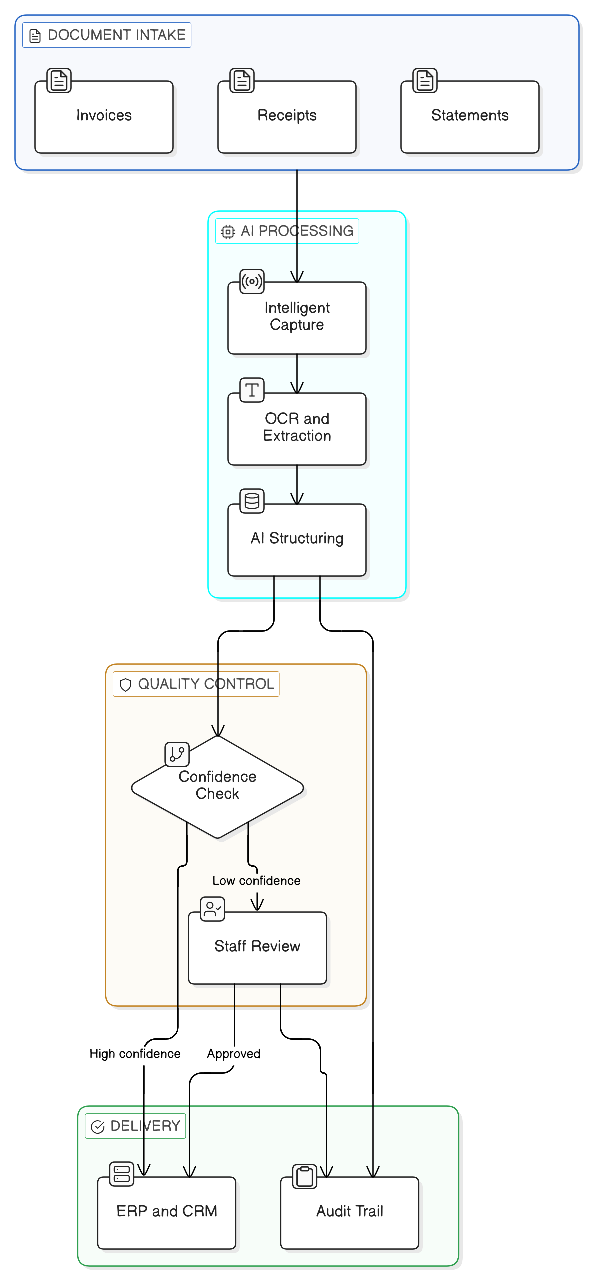
A pipeline that ingests documents, extracts structured fields, validates against schemas and business rules, and integrates outputs into downstream systems.
| Component | What It Does |
|---|---|
| Intelligent Capture | Ingests multiple formats, classifies documents, improves readability |
| OCR & Extraction | Hybrid extraction for complex layouts, tables, handwriting |
| AI Structuring | Maps content into target schemas with confidence scoring |
| Review Workflow | Human-in-the-loop for low-confidence fields, plus feedback loop |
| System Integration | Exports to ERP/CRM with field mapping and logging |
How It Runs
- Intake: PDFs arrive via email or folder drop
- Classification: Document type detected and routed
- Extraction: OCR plus field extraction into schema
- Validation: Confidence thresholds and rule checks
- Human checkpoint: Low-confidence fields reviewed and corrected
- Delivery: Structured output written to ERP/CRM
- Traceability: Every step logged for audit
Where Humans Stay in the Loop
- Low-confidence fields are queued for staff review
- Validation rules enforce required fields and formats
- Corrections are captured to reduce repeat errors over time
Operating Model
This changes how work flows through the team.
| Role | Responsibility |
|---|---|
| Exception Queue Owner | Reviews low-confidence extractions, typically 15 to 30 min/day at moderate volume, scales with exceptions |
| Review SLA | 24-hour turnaround on exception queue to prevent backup |
| Escalation Path | Unrecognized document types flagged for schema update |
| Audit Owner | Quarterly review of extraction accuracy and exception patterns |
What Transfers, What Must Be True
What transfers
- Schema-based extraction with confidence scoring is the reliable pattern
- Human checkpoints for low-confidence items catch errors without slowing throughput
- Audit trail is non-negotiable in regulated or compliance-sensitive work
- The pattern works across industries (legal, accounting, healthcare, insurance)
What must be true in your environment
- You can define target schemas and done criteria
- Your documents have enough consistency to classify reliably
- Your downstream system accepts structured inputs
- Someone owns the exception queue and has time carved out for it
Failure Modes
What breaks this pattern:
Uncontrolled document variability
If every document is a snowflake, extraction accuracy drops and exception volume overwhelms the queue.
Missing or shifting schemas
No target schema means no validation. Shifting schemas break the pipeline.
Weak exception ownership
If nobody owns the queue, it backs up and the system loses trust.
No downstream integration
Manual re-entry after extraction defeats the purpose.
Directional Outcomes
In similar workflows, teams typically see major cycle-time reduction and high extraction accuracy once the review loop is tuned.
| Metric | Estimate | Basis |
|---|---|---|
| Extraction accuracy | ~95% | Typical for structured documents with hybrid OCR plus LLM |
| Speed improvement | ~30x | Manual entry at 5 to 10 min/doc vs seconds automated |
| Processing time reduction | ~85% | End-to-end cycle, including review queue |
| Labor per document | Order-of-magnitude reduction | Based on FTE time reclaimed, varies with volume and complexity |
| Annual savings | $150K to $200K range | Modeled on volume and hourly rates, yours will differ |
Architecture
Stack
| Layer | Technology | Why |
|---|---|---|
| Backend | Pipeline orchestration framework | Robust multi-step workflow management |
| AI/ML | OCR engine + LLM extraction | Handles layout variety and ambiguity |
| Database | Relational store | Structured storage with full audit trail |
| Architecture | Stateful workflow (Tier 3) | Human checkpoints, learning from corrections |
Want to see if this pattern fits your documents?
We can review 10 to 20 samples from your workflow and estimate automation coverage before building anything.